
3주차 수업 내용
▶ 다중공선성 Multi - Collinearity
- 개념
- 서로 다른 독립변수들이 거의 같은 정보를 담고 있어 서로 중복된 설명력을 가지는 현상이다.
- 주로 선형회귀, 로지스틱회귀 모델에서 발생하는 문제이다.
- 문제점
- 회귀계수 불안정
- 표준오차( standard error )가 커져서 회귀계수의 추정치가 민감해진다.
- 데이터가 조금만 변해도 회귀계수가 크게 달라질 수 있다.
- 해석의 어려움
- 각 독립변수가 종속변수에 미치는 개별 효과를 정확히 분리하기 어렵다.
- ex) X1과 X2가 매우 비슷하면, 어느 변수가 실제로 Y를 설명하는지 구분하기 힘들다.
- 통계적 유의성 왜곡
- 전체 모형은 유의하지만, 개별 변수의 t-value 값이 작아져서 유의하지 않게 보일 수 있다.
- 회귀계수 불안정
- 진단 방법
- 상관계수 행렬
- 독립변수 간의 피어슨 상관계수(|r|>0.8 이상) 확인.
- 분산팽창계수(Variance Inflation Factor, VIF)
- 일반적으로 VIF > 10 (또는 보수적으로 VIF > 5)이면 공선성이 심각하다고 본다.
- 다중 공선성이 큰 변수는 선형회귀 모델에서 제외시킨다.
- 상관계수 행렬

▶ 릿지 Ridge, 라쏘 Lasso
- 공통된 개념
- 다중공선성 을 완화하고 과적합(overfitting)을 방지하기 위해 개발된 정규화(regularization) 기법이다.
- 두 방법 모두 선형회귀 모델의 손실함수에 규제항(penalty term) 을 추가하지만, 패널티의 방식에 따라 차이가 있다.
- 릿지 (Ridge)
- L2 규제 : 계수의 제곱합을 규제함으로써 전체 계수를 작게 축소(shrinkage) 시킨다.
- 특징
- 계수를 0에 가깝게 줄이되 완전히 0으로 만들지는 않음.
- 공선성이 있는 변수들이 있을 때 계수를 함께 축소해 안정성을 확보.
- 모든 변수가 조금씩 영향을 주는 상황에서 강력함.
-
- 장점
- 다중공선성 완화에 특히 효과적.
- 모든 변수를 유지하되 계수를 작게 만들어 해석을 유지.
- 단점
- 불필요한 변수를 완전히 제거하지 못함 → 변수 선택(variable selection)에는 한계.
- 장점
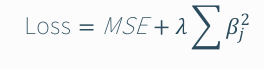
- 라쏘 (Lasso)
- L1 규제 : 계수의 절댓값 합을 규제함으로써 일부 계수를 아예 0으로 만들어 변수를 제거한다.
- 특징
- λ가 커질수록 일부 계수가 정확히 0이 됨.
- 불필요한 변수를 자연스럽게 제거 → 변수 선택 기능 내재.
- 장점
- 해석 가능한 간결한 모델 생성.
- 고차원 데이터(변수 수가 표본보다 많을 때)에서 특히 유용.
- 단점
- 강한 상관관계가 있는 변수들 중 한두 개만 선택하고 나머지를 0으로 만들어버릴 수 있음 → 정보 손실 위험.
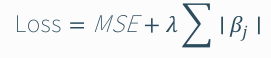
수업 코드
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.linear_model import LinearRegression
------------------------------------------------------
# 데이터 준비
data = '데이터 파일 불러오기'
## 데이터 분할 : x,y 나누기
target = '예측하고 싶은 변수'
x = data.drop(target, axis=1)
y = data.loc[:, target]
## 첫번째 가변수 제거
cat_cols = ['가변수화 할 변수']
x = pd.get_dummies(x, columns=cat_cols, drop_first=True)
## 데이터 분할 : train, validation 나누기
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random_state = 20)
-------------------------------------------------------------
# 모델링
features = ['학습에 사용할 변수 지정' ]
x_train1 = x_train[features]
x_val1 = x_val[features]
model1 = LinearRegression() # 모델 선언
model1.fit(x_train1, y_train) # 모델 학습
print(model1.coef_, model1.intercept_) # 회귀계수, 절편 출력
pred1 = model1.predict(x_val1) # 모델 예측
## 모델 평가
print('RMSE :', root_mean_squared_error(y_val, pred1))
print('MAE :', mean_absolute_error(y_val, pred1))
print('r2 :', r2_score(y_val, pred1))
---------------------------------------------------------
# 릿지, 라쏘 모델링
from sklearn.linear_model import Ridge, Lasso # 라이브러리 불러오기
## 릿지 모델링
ridge_model = Ridge(alpha=1) # 모델 선언 # alpha : 규제 강도
ridge_model.fit(x_train, y_train) # 학습
pred_r = ridge_model.predict(x_val) # 예측
## 평가
print('RMSE :', root_mean_squared_error(y_val, pred_r))
print('MAE :', mean_absolute_error(y_val, pred_r))
print('r2 :', r2_score(y_val, pred_r))
## 라쏘 모델링
lasso_model = Lasso(alpha=1) # 모델 선언 # alpha : 규제 강도
lasso_model.fit(x_train, y_train) # 학습
pred_l = lasso_model.predict(x_val) # 예측
## 평가
print('RMSE :', root_mean_squared_error(y_val, pred_l))
print('MAE :', mean_absolute_error(y_val, pred_l))
print('r2 :', r2_score(y_val, pred_l))3주차 수업을 마무리하며
오늘부로 3주차 수업이 마무리가 되었어요.
빅데이터 분석 학회인 BDA 학회의 모델링 수업을 들으면서 점차 모델링과 친해지고 있는 느낌이 들었습니다.
강사님이 개념부터 차근차근 이해하기 쉽게 설명해주셔서 (물론 저는 전공자이지만) 비전공자분들이 듣기에도 한번에 이해할 수 있을 것 같다는 생각이 들었어요.
강의를 듣다가 놓친 부분이 있어도 복습 동영상을 통해 다시 들을 수 있어서 너무 편리했어요.
저는 복습 과제를 진행하면서 전에 배웠던 내용을 상기 시키기 위해 복습 동영상을 참고했는데, 다시 스스로 공부할 때 이해가 안갔던 부분을 돌려볼 수 있어서 너무 유용하게 활용했답니다.
아직 3주차밖에 되지 않았지만, 강사님과 BDA 운영진분들이 수강생에게 얼마나 관심이 많은지 알 수 있었어요.
수업이 끝나고 Q&A 방에 질문을 올리면, 강사님이 너무 친절하게 열심히 설명해주셔서 감동이였어요 ..
앞으로의 수업도 너무 기대가 됩니다.
16주차까지 열심히 달려볼게요.
다음 포스트에서 만나요 ~
'대외활동' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링반 ML1 5주차 (0) | 2025.11.17 |
|---|---|
| [BDA 11기] 데이터 분석 모델링반 ML1 4주차 (0) | 2025.10.13 |
| [BDA 11기]데이터 분석 모델링반 ML1 2주차 (1) | 2025.09.19 |
| [BDA 11기] 데이터 분석 모델링반 ML1 1주차 (1) | 2025.09.15 |



